
Because Hard Drives Don’t Grow on Trees
If you’re running your own antenna-based DVR with an HDHomeRun at its core, you’ve probably got a fair amount of recordings – very large .ts files – taking up space.
That’s because under the ATSC 1.0 broadcast standard, most broadcast video in the USA (like 99%) is transmitted as an H.262 MPEG-2 video stream. This now-ancient codec (defined in 1994, adopted into ATSC 1.0 in 2004) is not very efficient, so the .ts files that house them are freaking huge.
If you’re looking to save space, you’ll want to transcode those files to H.265 HEVC. The quality loss will be negligible, and the space savings will be dramatic.
How Dramatic?
Results will vary, but a 60 minute, 720p video of an MPEG-2 broadcast streamed at about 5Mbps takes up 2.6 GB.
After converting it to HEVC? 631 MB.
Doing the Thing
You’ll use the swiss army knife of video, ffmpeg, to convert your files. Like all of the best open source software, ffmpeg is ancient, it’s free, and – bonus – it’s also very hard to use.
My original goal was to convert all of my recorded files on a 1:1 basis. Just a straight conversion from TS to MKV.
I wanted to end up with the files I would have had if HEVC/H.265 had been part of the ATSC 1.0 spec.
In an absolutely perfect world, you would convert a .ts file to an .mkv file like so:
ffmpeg -i input.ts -c:a copy -c:s copy -c:v libx265 output.mkvIt’s “elegant” in much the same way that an off-duty ballerina with a broken leg might step off of a train. You can sort of tell what it’s trying to do but maybe a wheelchair is called for.
So let’s break that down:
-i input.ts [your input file]
-c:a copy [copy all audio streams to the output file without altering them]
-c:s copy [copy all subtitle streams to the output file without altering them]
-c:v libx265 [encode the video using the h265 software encoder]
output.mkv [your output file]This works!
Sort of.
Unfortunately it’s never that easy with ffmpeg. Your output file will look and sound great – but none of your Closed Caption data will have made the journey. Where did it go?
Why didn’t this work?
A few reasons.
Unlike many video formats, MPEG-2 captions are technically “captions” not “subtitles”. The difference is that subtitles live in their own dedicated stream within a video container. “Closed Captions” don’t have a dedicated lane like subtitles do and are instead embedded within a file’s video stream(s). There’s no “caption stream” to copy! This is sort of a holdover from the analog TV days.
Furthermore! These captions are encoded with the EIA-608 / EIA-708 standards. The .mkv container only accepts a handful of subtitle codecs, and they are not included. To get around this we need to use an ffmpeg filter to extract the captions from the video stream first, and we then re-encode them using a format that .mkv accepts.
Wow this is getting complicated. I’m annoyed.
The .mkv container officially supports just four subtitle codecs: srt (“SubRip”), ssa (“SubStation Alpha”), ass (“Advanced SubStation Alpha”), and vtt (“WebVTT”). You’ll have to convert the subtitles to one of those in your output file.
Let’s Transcode
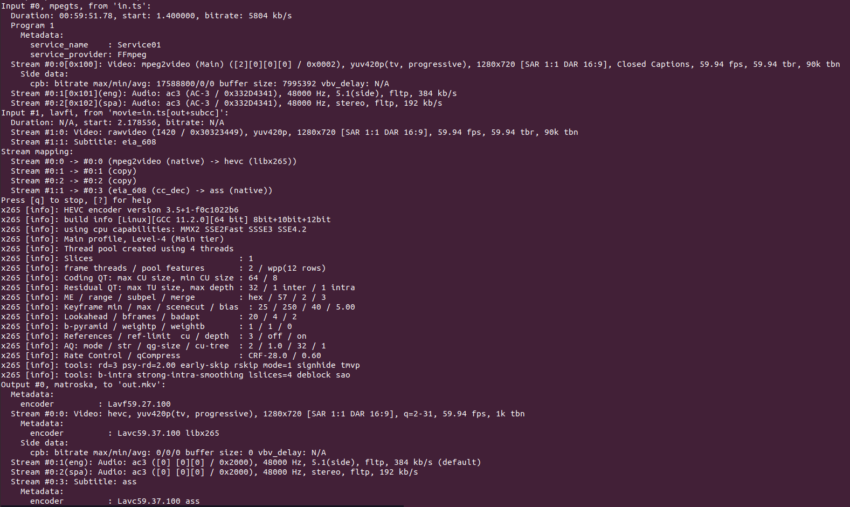
Here’s the magic line that should work, but doesn’t really.
ffmpeg -i in.ts -f lavfi -i movie="in.ts[out+subcc]" -map 0 -c:v libx265 -c:a copy -map 1:s -c:s srt out.mkvNote that we’re using two separate inputs to create one output file. The “[out+subcc]” forces ffmpeg to treat the captions as an actual subtitle stream.
Here’s what does what:
-i in.ts [first input ('input 0') - includes everything ffmpeg can read on its own]
-f lavfi -i movie="input.ts[out+subcc]" [second input ('input 1') - this exposes the captions as if they were a subtitle stream]
-map 0 [map all streams (audio, video, and non-existent subtitles) from 'input 0']
-c:v libx265 [encode the video using the h265 software encoder]
-c:a copy [copy all audio streams without altering them]
-map 1:s [map all subtitle streams from 'input 1']
-c:s srt [convert closed captions to the srt subtitle format]
out.mkv [output file]We’ve now got a converted file. But all is still not well with the subtitles…
EIA-608 / EIA-708 and SRT
ffmpeg’s support of Closed Caption data is experimental and unpredictable.
EIA-608 was the captioning standard used by analog TV. EIA-708 is the standard used by digital TV. There’s a great post over here that explains the differences between the two.
All TV may be digital now, but many (most) US broadcasts include both EIA-608 and EIA-708 captions. ffmpeg struggles to decode these.
When you extract captions using ffmpeg, sometimes (but not always) all caption text will inexplicably be converted to “HEHEHEHEHEHEHEHEHEHEHEHE” repeated over and over. I’m not even joking. This is a thing that really happens.
If you do manage to successfully extract captions, they will lose all of their formatting when you ask ffmpeg to encode them to an embedded .srt stream. At that point all of your captions will show up in the top-left corner of the screen instead of the bottom-center where they belong.
What the shit!
So okay, srt won’t work. You’ve got to encode your captions to either vtt or ssa/ass instead.
Yes, that’s a solution. But it’s also a compromise. SRT is ubiquitous. It’s the best-supported subtitle format in the world. You want to use srt.
ARGH. Why is this so HARD AND STUPID?
Do It For Real
So, look. You probably came into this process hoping to use ffmpeg for everything. Like I did!
The reality is that you can’t.
We’ve established that ffmpeg can’t be relied upon to extract broadcast (US-based) Closed Captions reliably. We’ve also established that it struggles to retain proper text formatting of said captions during certain types of subtitle encoding.
We need to pull in an expert. That expert is ccextractor. This thing does subtitles and subtitles only.
In two steps, we have what we need:
ccextractor in.ts
ffmpeg -i in.ts -i in.srt -map 0 -c:v libx265 -c:a copy -map 1 -c:s srt -metadata:s:s:0 language=eng out.mkvThe ffmpeg syntax here is very different than before.
First we extract subtitles from the source file using our new friend, ccextractor. That’ll create a beautiful .srt file full of flawlessly-formatted captions. At last!
Finally we inject those subtitles into the output file and mark them as English:
-i in.ts [First input file ('input 0')]
-i in.srt [Second input file ('input 1')]
-map 0 [map all streams (audio, video, and non-existent subtitles) from the first input ('input 0')]
-c:v libx265 [encode the video using the h265 software encoder]
-c:a copy [copy all audio streams without altering them]
-map 1 [map all streams from the second input ('input 1')]
-c:s srt [ensure the output file contains captions as SRT]
-metadata:s:s:0 language=eng [Set subtitle language to English]
out.mkv [output]So that’s all good then. We’ve transcoded, we’ve got an output file with captions, and it all works!
We could just stop here! In fact, you can stop here. If you want to get a little fancier, read on…
Multiple Captions
You may have noticed that ccextrator dumped out not just one srt file, but two or more.
I mentioned up above that a lot of broadcasts include captions encoded in both the old and new standards. These are those.
You may end up with more than two files, but at a minimum:filename.srt are the EIA-608 captions.filename.p1.svc01.srt are the EIA-708 captions.
Up above we’re using the 608s and converting to srt. Nothing wrong with that. It’s plain text. There’s nothing really fancy about it. It works.
Why would we want to use 708s? 708 captions allow for broadcasts to specify things like different text sizes, usage of different fonts, changes in color, and support for special characters. If 608s are a newspaper, 708s are full-color magazines.
There’s a misconception out there that .srt files don’t officially support color. They do. They just don’t support all of what 708 brings to the table. They don’t support the use of alternate fonts and font sizes, among other things. If we want to use the 708s with all supported features, we’ll need to compromise and use .ass or .vtt for subtitles.
The commands then change slightly:
ccextractor in.ts
ffmpeg -i in.ts -i in.p1.svc01.srt -map 0 -c:v libx265 -c:a copy -map 1 -c:s ass -metadata:s:s:0 language=eng out.mkvWhew. That’s it. We are DONE!
Technically you could do a little more work to include any other multi-language subtitles that ccextractor may have pooped out, but that’s more work than I’m willing to put in for captions I’d never use anyway.
What about hardware encoding?
That’s the first thing I tried. And let me tell you, hardware encoding is not all it’s cracked up to be.
I spent a long time experimenting with a hardware encoder (QSV) and it’s definitely faster. However the output files never looked quite as good as software-encoded files of similar size. In fact they looked like straight ass. So I gave up on it.
Hardware transcodes are fine for real-time viewing. But what’s the rush? We’re working on files that have already been recorded. We can take our time to focus on quality.
Are you sure this is right?
I’m 95% sure this is the most efficient way to do all this.
Look, I’m not an ffmpeg master. More like an ffmpeg tolerator. Actual broadcast engineers use this tool in their day jobs. I am not one of them.
If there’s a better, more effective syntax to accomplish all this, feel free to drop it in the comments.
Can I automate this?
Yes!
There are two semi-great tools that will automate the transcoding process for you: Tdarr and Unmanic. Both have decent web UIs that let you schedule any CPU-intensive transcodes so that they only occur during late-night hours.
Unfortunately the goal of each tool is to more or less take full control of ffmpeg out of your hands in the name of simplicity. Neither tool will let you specify two separate inputs in a single ffmpeg command, and they both use complicated plugin systems that only let you customize so much.
I wrote a script that a cron job runs every morning at 1am. It’ll scan an entire library for .ts files and will only start new transcoding jobs within the hours of 1 and 5am using the commands above.
Once the script works its way through my entire recorded library, I can expect all new recordings to exist in their supersized versions for no more than a day or so before they’re auto-converted and fed right back into Plex.
ATSC 3.0 should fix all of this
Right now ATSC 3.0 (they skipped 2.0) uses the H.265 HEVC codec by default, and the door was left open for additional codec support in the future. That’s great, right?
Well, yes and no. The files may be smaller and we won’t need to do all this transcoding baloney, but the entire 3.0 standard is hampered by the inclusion of consumer-hostile DRM (Digital Rights Management). It’s possible that the files you record may be locked away and/or encrypted, rendering them untouchable by tools like ffmpeg or even Plex. Too soon to say for sure, though.
THANK YOU. I’ve been trying to figure this out for months. It shouldn’t be this hard. And you’re right, the DRM in ATSC 3.0 means I’m sticking with 1.0 for as long as I possibly can.
708 captions are fascinating to me. It seems like they’re capable of so much, but everyone’s just using them in the same way they’ve used 608s. Have you seen any of those advanced features in use at all?
Hi!
In my area, no. 99% of the time, 708 and 608 displays are identical. Sometimes I’ll see text color changes, but that’s extremely rare, and I think I’ve only ever seen that happen on PBS broadcasts.
I still haven’t seen different fonts or text sizes used at all. Which is probably for the best…